{kind=link}
Edge computing is to the cloud what the thin-client is to the Unix terminal. With a sense of deja-vu, you can look at enterprise IT going from a highly-centralized model to distributed client-server architectures and back to centralizing computational power and data in the cloud.
But here is a question: what are we supposed to do when we can’t afford a couple of seconds to spare for processing in the cloud (network problems, latency when transmitting data)? With the explosive growth of connected devices, the problem we will have to deal with is where to get a fat network pipe for data that is produced at massive rates every day.
What is edge computing?
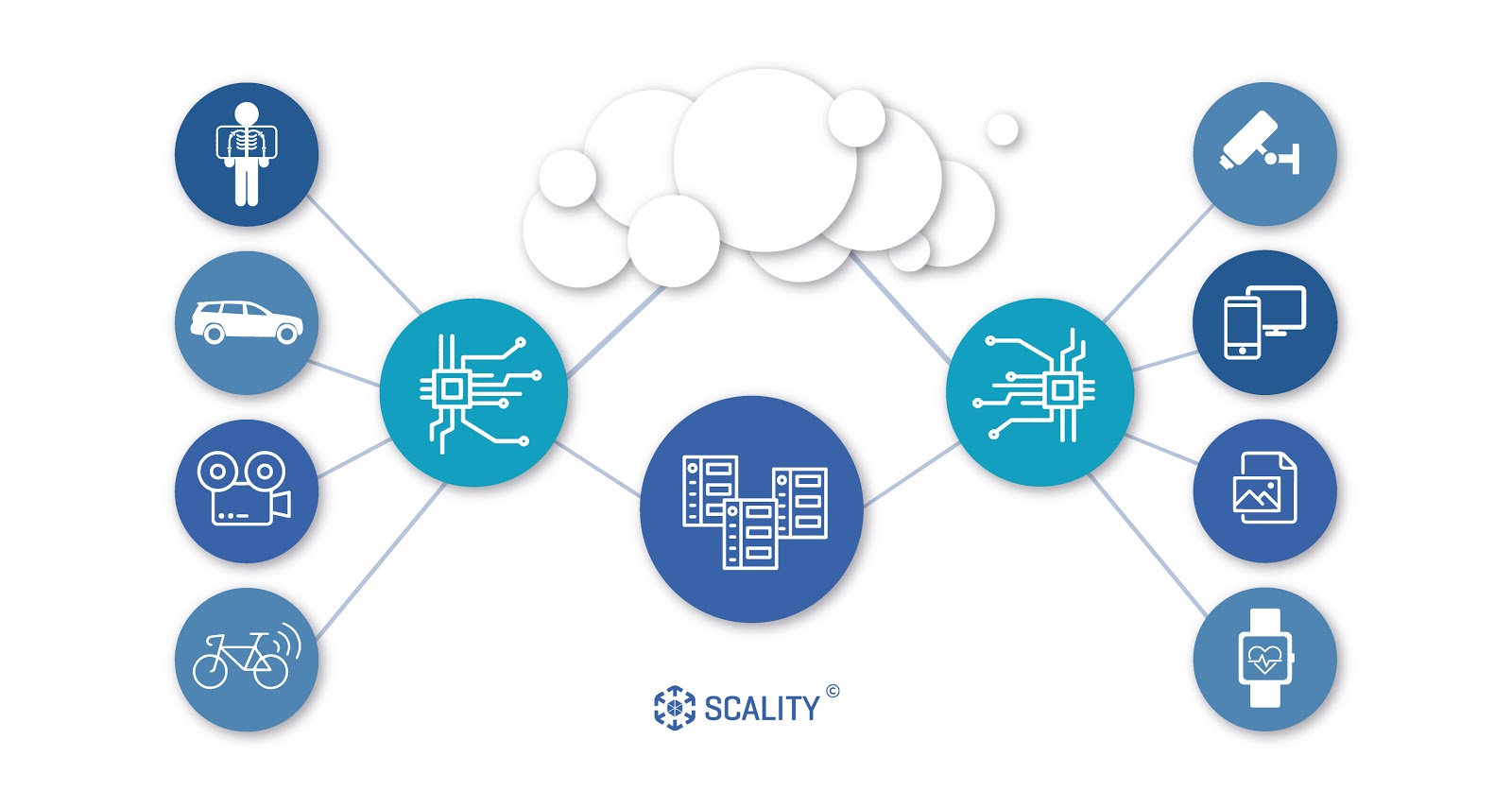
An edge device is where data is gathered – your phone, your car, your fridge. Edge computing is the act of collecting, storing data, and processing what’s possible near that edge device (or within it) and then sending only important information to the cloud for an update or only data that really needs heavy computational resources.
FUN FACT: The original idea of edge computing was born in the 1990s with the CDN (Content Delivery Network) that solved the problem of web traffic jams. The solution is to store and deliver web pages to the users based on geo location (from the closest node to the user).
Take the case of modern cell phone towers. This is edge computing at its most direct – you continually switch to the closest tower as you travel. As we transition from 4G to 5G networks in the near future, edge computing makes sure the fast bandwidth possibilities of 5G are realized. The closer your data and access to a network are, the more useful the connection. We’ll most likely see this potential in smaller devices, from on-site video processing mapping robots to wearable smart glasses, but be ready for edge computing and 5G to work together a lot more (and with plenty of other devices) in the future.
Why edge computing
Edge computing optimizes and extends the capability of cloud computing infrastructure. Centralized cloud processing and unlimited scaling work well in most instances, but latency is still an issue.
One of the biggest advantages of edge computing, of course, is nearly real-time data processing. Within industries like autonomous vehicles and healthcare losing even a fraction of a second could be a life and death situation. Instead of sending big chunks of data to some central cloud location, important processing and decisions are made fast, on the edge.
Edge computing is also more secure for storing and processing personal and sensitive data within (or close to) the devices collecting that data. This reduces network exposure and as a result minimizes the possibility of attack. For example, processing patients’ health information on the edge eliminates the privacy concerns of transferring and storing data in remote cloud data centers, ensuring better privacy regulations compliance.
Fog computing
There is another concept that goes hand in hand with both edge and cloud computing. Fog computing (the name metaphor implies “closer to the ground”) is a distributed network architecture that connects the logical network’s end (edge devices) with the central cloud. In other words, fog computing is small data centers located near the edge where data is being produced.
It’s a low-latency transfer point where data can be stored or analyzed and pushed further if needed. This allows to significantly reduce the amount of bandwidth needed to send data to the cloud and offers much faster and safer processing close to the edge, almost like a mixed-use strategy. Edge computing and fog computing play well together to create an ecosystem for the growing amounts of data produced by connected devices.

Where edge computing is helpful
There are many industries that already benefit from edge computing and this tendency will only spread. CBinsights lists five cases where edge computing is ready to make an impact:
- Transportation, like autonomous vehicles, produce incredible amounts of data and require fast processing to deliver a decision. Don’t forget about planes, trains, and other transportation solutions. Self-driving or not, they are all equipped with sensors collecting crucial data that needs to be acted upon quickly.
- Healthcare imagery and all kinds of health tracker devices require fast, private processing, an ideal use of edge and fog computing.
- Agriculture (smart farms), with remote locations, can have bad or no network connections at all but they’re equipped with all kinds of sensors and IoT devices.
- Manufacturing is already almost fully automated which means the whole process is controlled by analyzing the data from various sensors inside the factory’s robotics.
- Personal devices and gadgets will of course look to foster, more private connections via edge and fog computing.
All of the above employ machine learning already, demanding some serious computational power and lots of data. Tech giants have made colossal progress in edge AI between 2017 to 2018. Intel released its vision chip Myriad X that can process computer vision applications in real-time – it’s intended to be installed in the device. Apple developed its neural engine with iPhone 8 (that’s three device generations ago)to handle face recognition directly the device. Imagine how annoying it would be to wait for data to get to the cloud, get processed there and come back? And more importantly, think about how insecure that would be.
Edge is our future
The amount of produced data by IoT devices already feels like a flood. It’s only going to get worse; a normal person will produce 1.5 GB of data per day by the year 2020. Autonomous vehicles will produce up to 4000 GB per day, per vehicle. That’s a ton of data that will need to be processed, analyzed, and returned to users efficiently, safely, and privately.
Edge computing as infrastructure is still in its infancy, but we can expect to see big investments in the technology by major corporations. It won’t be very long before we see it used for everything that needs fast, private connections, from IoT to autonomous vehicles, personal and medical data, and even the cloud itself.